Multicore Processing
 3ds Max is not a software optimized for multicore machines even though in the recent years subcomponents of 3ds Max got an update. And although not every component can and should be parallelized (please also see Autodesk Knowledge Network) there are certainly tasks whose performance would benefit from parallelization. In VFX we typically work with a lot of objects, a lot of particles... a lot of data! And thats where you should consider to parallelize your tasks. In addition, Desktop-CPUs with up to 64 cores (and in the future certainly even more cores) are available right now.
3ds Max is not a software optimized for multicore machines even though in the recent years subcomponents of 3ds Max got an update. And although not every component can and should be parallelized (please also see Autodesk Knowledge Network) there are certainly tasks whose performance would benefit from parallelization. In VFX we typically work with a lot of objects, a lot of particles... a lot of data! And thats where you should consider to parallelize your tasks. In addition, Desktop-CPUs with up to 64 cores (and in the future certainly even more cores) are available right now.
The necessity of parallelization is especially true when working with particles in plugins like Thinking Particles. TP is a software that ships with well optimized and robust operators like the SC operator (shape collision) and because the possibilites of the procedural workflow are pretty much endless there are a lot of tasks that do not use the full power of your CPU. Fortunately Cebas offers the possibility of writing your own operators in Maxscript and combined with the .NET framework you have the freedom to write multithreaded script operators.
Sample Project

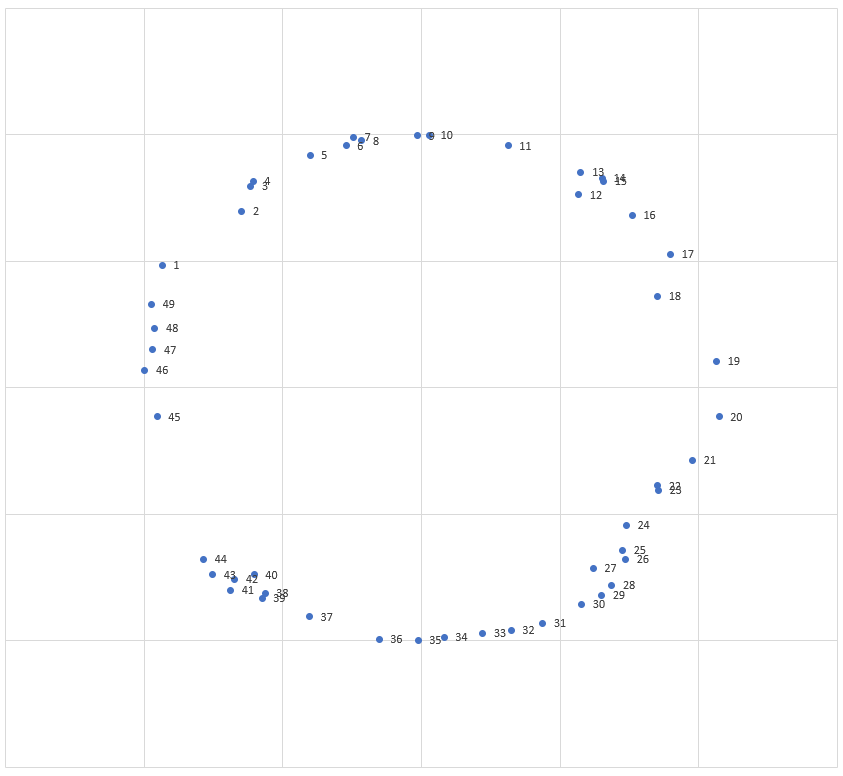
Let's discuss the benefits of parallelization with the help of a little sample task. Let's say we have hundreds of shapes like those three up there, that we generated procedurally. Furthermore there are randomly created points on the edge polygons of these shapes. We want to connect these points to each other so we get a continous spline. Because the points were generated randomnly, they are not in the correct order. Our goal is to bring these points in the correct order and generate a spline. For now we concentrate on the blue circle. To complicate things a little bit we distort the circle to a certain degree in the X-direction. We get the following points. Because this is an illustrative example, we remain in the two-dimensional space.
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | ... | |
| X | -93,54594 | -57,50882 | -15,27762 | 65,69775 | 106,4364 | -21,51347 | -68,84601 | -99,7496 | -24,55 | -78,61927 | ... |
| Y | 48,32915 | -83,17915 | -99,5687 | 81,676 | 10,60175 | 97,65844 | -80,11526 | 7,072217 | 98,93582 | -67,67719 | ... |
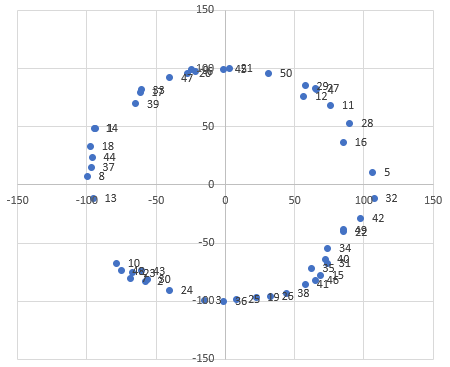 As you can see in the image and in the table we have to reorder the points before we can connect them to generate a spline. At first sight it seems to be a simple task. We stick together some nodes in TP that search for the nearest point. But this would be a very error-prone approach, that rarely leads to the correct order. As trying all permutations is impractical (see also TSP in general) we instead implement Simulated Annealing with the 2-opt algorithm as the local search algorithm. In this way we will likely obtain the global distance minimum. For hundreds of shapes (with e. g. 500 points each) this leads to a reasonable computation time (single-threaded as well as multi-threaded).
As you can see in the image and in the table we have to reorder the points before we can connect them to generate a spline. At first sight it seems to be a simple task. We stick together some nodes in TP that search for the nearest point. But this would be a very error-prone approach, that rarely leads to the correct order. As trying all permutations is impractical (see also TSP in general) we instead implement Simulated Annealing with the 2-opt algorithm as the local search algorithm. In this way we will likely obtain the global distance minimum. For hundreds of shapes (with e. g. 500 points each) this leads to a reasonable computation time (single-threaded as well as multi-threaded).
Simulated Annealing - Algorithm
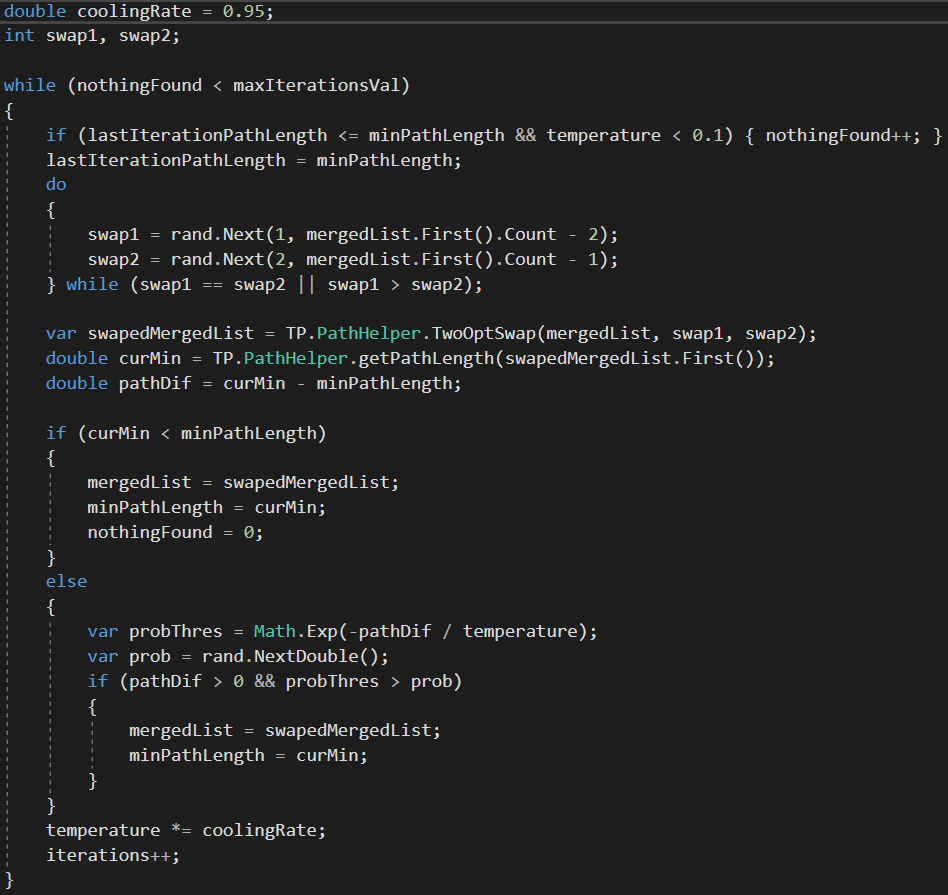 What you can see on the right is the essential part of the implementation of the algorithm in C#. Ideally, we want this code to run on a separate thread for each shape. I encapsulated some parts of the code like the actual swap in the PathHelper class living inside the TP namespace.
What you can see on the right is the essential part of the implementation of the algorithm in C#. Ideally, we want this code to run on a separate thread for each shape. I encapsulated some parts of the code like the actual swap in the PathHelper class living inside the TP namespace.
As you might have also noticed I chose a fixed cooling rate of 0.95. Thats why no cooling rate parameter is exposed to the Thinking Particles UI.
The else statement ensures that we can escape from local minima (assuming we have chosen appropriate initial parameters). The acceptance probability is defined in the else statement as euler's number raised to the power of the paths difference (negative) divided by the temperature.
TP Script Operator
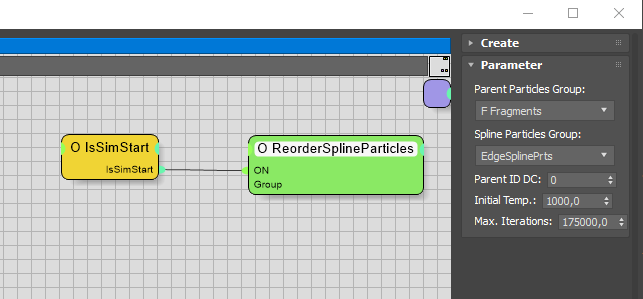
Writing a custom TP a basic script operator isn't to difficult. Joe Scarr has some great ressources out there you can follow along to get you started (e. g. here).
A TP script operator for our use case of reordering particles may look like the one on the left. As we are going for a multi-threaded approach we need to store the ID of each shape - here in the parameter tab called "Parent ID" (data channel 0). This way we are prepared for using one thread per shape (in case the TPL decides so or we force this degree of parallelization). Additionally we can provide our Simulated Annealing algorithm with an initial temperature and an exit condition (max iterations). We have to set the initial temperature high enough to escape local minima, an acceptance probability of 0.8 could be a first step.
Result
 After the script operator (including our DLL) has completed we get the result and can ascertain that the particles are in their expected positions. Usually the approach described above leads to a CPU-usage of 100 % when performed on many objects. With a 32 core CPU or even 64 core CPU this can speed up your calculations tremendously.
After the script operator (including our DLL) has completed we get the result and can ascertain that the particles are in their expected positions. Usually the approach described above leads to a CPU-usage of 100 % when performed on many objects. With a 32 core CPU or even 64 core CPU this can speed up your calculations tremendously.